第一章:Transwarp Manager的安装
安装前准备
修改\/etc\/hosts文件内容
在\/etc\/hosts文件中添加主机名,添加在最后一行,如192.168.1.200 dhc-1(注意hostname不支持使用'_','.'),配置完成后可以互相ping下,如果ping不通,请检查\/etc\/hosts文件和静态IP的设置
关闭防火墙
使用chkconfig iptables off关闭防火墙,并使用chkconfig iptables --list查看其状态
安装目录的创建-非必选
在\/mnt目录中创建disk1目录(若配有SSD固态硬盘还需创建randisk目录)
时间设定-非必选
设置系统时间为NTP网络时间(如date -s '2016-1-19 9:00:00')
\/etc\/sysconfig\/network文件修改
NETWORKING=yes
HOSTNAME=dhc-1
- ip地址修改
vi /etc/sysconfig/network-scripts/ifcfg-eth0
#描述网卡对应的设备别名,例如ifcfg-eth0的文件中它为eth0
DEVICE=eth0
#设置网卡获得ip地址的方式,可能的选项为static,dhcp或bootp
BOOTPROTO=static
BROADCAST=192.168.0.255 #对应的子网广播地址
HWADDR=00:07:E9:05:E8:B4 #对应的网卡物理地址
#如果设置网卡获得 ip地址的方式为静态指定,此字段就指定了网卡对应的ip地址
IPADDR=12.168.0.33
NETMASK=255.255.255.0 #网卡对应的网络掩码
NETWORK=192.168.0.0 #网卡对应的网络地址
- 网关地址修改
vi /etc/sysconfig/network
#表示系统是否使用网络,一般设置为yes。如果设为no,
#则不能使用网络,而且很多系统服务程序将无法启动
NETWORKING=yes
#设置本机的主机名,这里设置的主机名要和/etc/hosts中设置的主机名对应
HOSTNAME=centos
#设置本机连接的网关的IP地址
GATEWAY=192.168.0.1
- DNS修改
vi /etc/resolv.conf
- 网络服务重启
service network restart
安装步骤:
一、进入\/mnt\/disk1目录
二、使用root用户解压其中的transwarp安装包并安装
>tar -zxvf transwarp-4.2.2-19029-zh.el6.x86_64.tar.gz
>cd transwarp
>./install
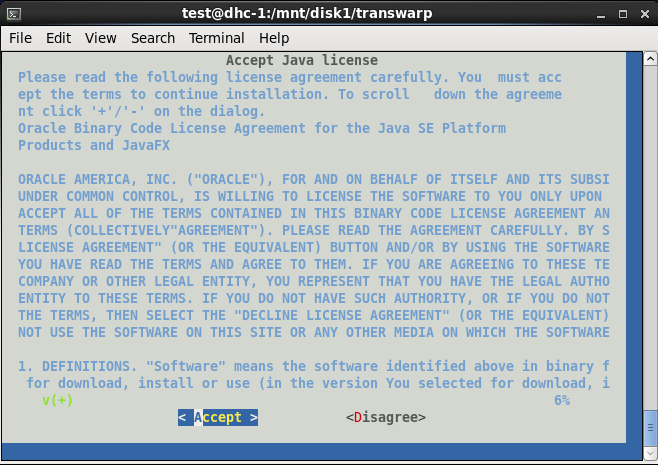
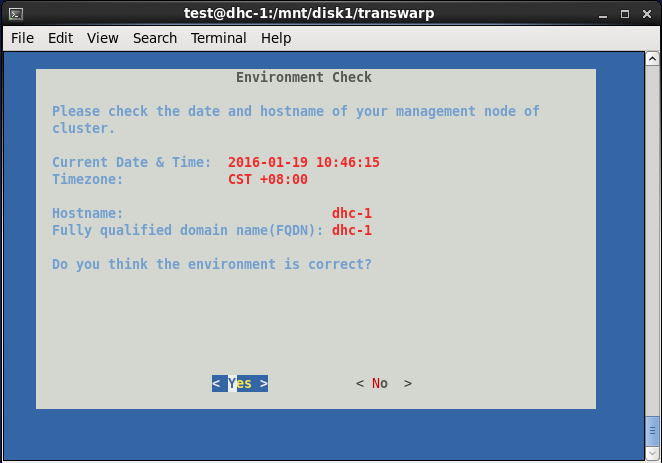
三、安装完成后,会自动弹出界面,依次选择Accept→选择网卡→默认端口8180→删除已有yum资源库→create new repository→Use ISO File→选择\/mnt\/disk1中的CentOS6.5安装包
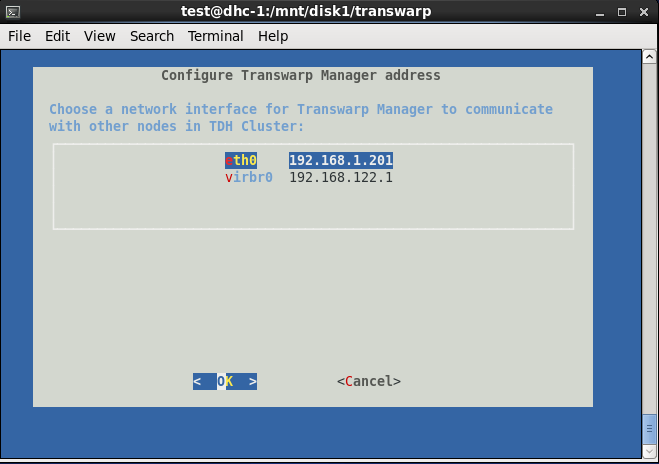
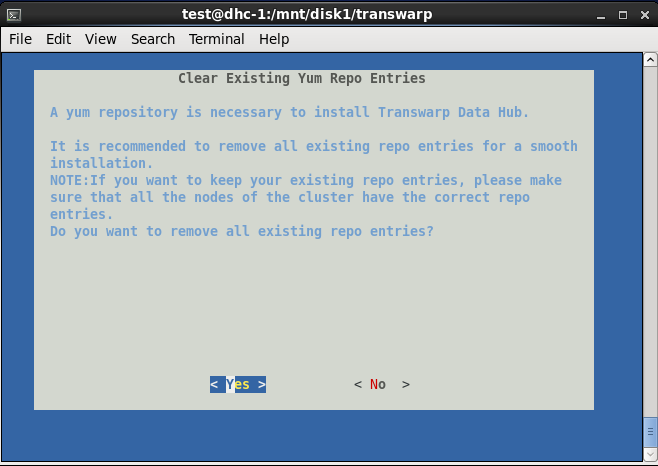
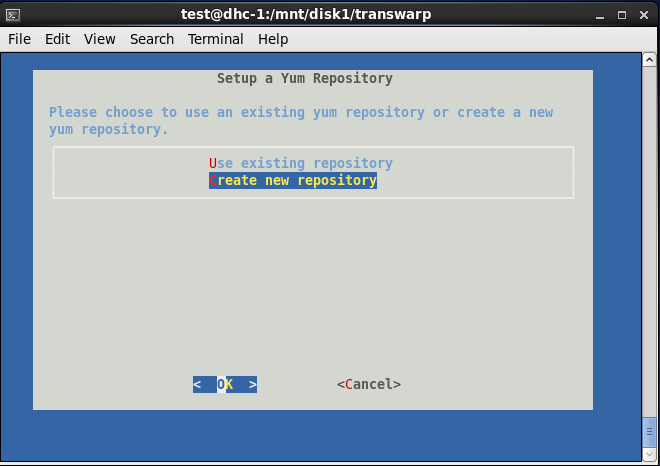
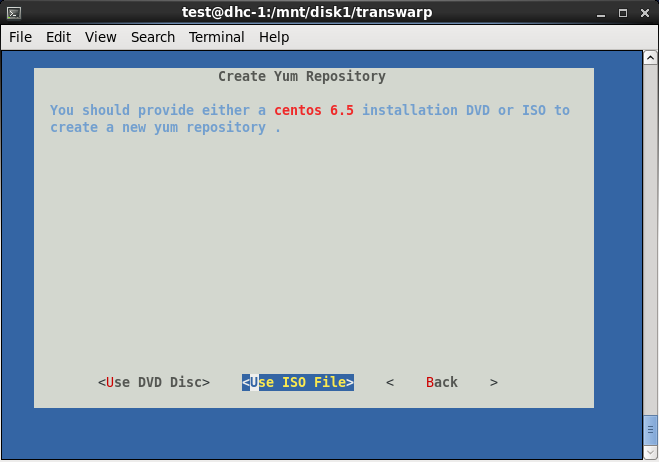
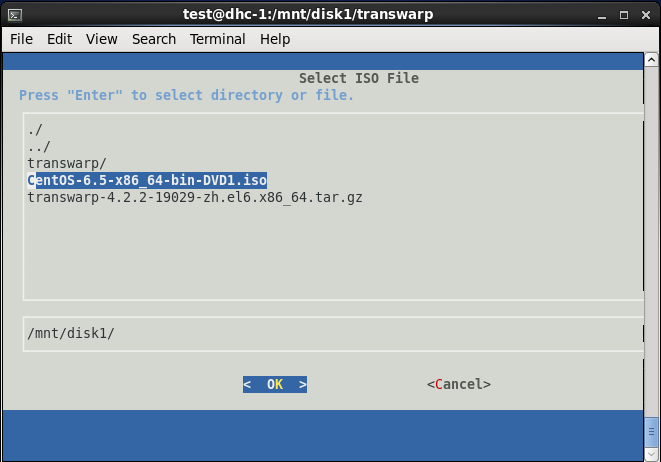
四、安装好Centos6.5以后,打开chrome浏览器,输入安装Manager的本地节点ip地址加端口号8180,如192.168.1.200:8180,进行如下步骤操作:
(1)输入admin、admin进入界面,为了方便多人对Mananger的操作,可以新建多个隶属于admin组的账户,同样可以操作服务器集群,避免了登入登出时被别的用户挤出。
(2)填写集群名称(随意取名)
(3)添加机柜(使用\/rack1,\/rack2......)指定
(4)添加节点(可以使用[]来批量添加,如172.16.2.[68-70])
(5)输入root账号和密码进行确认设定
(6)分配机柜,将刚刚的第一个节点分配到\/rack1中,其他两个节点分配到\/rack2中
(7)选择需要\/etc\/hosts来确认网络解析
(8)为了负载均衡,将YARN分配到\/rack1中,Inceptor-server分配到\/rack2中
五、安装组件和服务,按照左侧栏提示分别需要安装Zookeeper、HDFS、YARN、Hyperbase、Inceptor-SQL,其他可以暂时不用安装
(1)Zookeeper:将全部节点都添加上(一定要为奇数),其他默认
(2)HDFS:记住两个重要目录即可,分别为dfs.namenode.name.dir和dfs.datanode.data.dir,分别在\/home\/hadoop节点下的hdfs_image和data目录下。另外需要特别注意的是,在安装HDFS过程中可能会遇到formatnamenode失败的现象,查看界面上的操作日志,可以看到报以下这个错误:
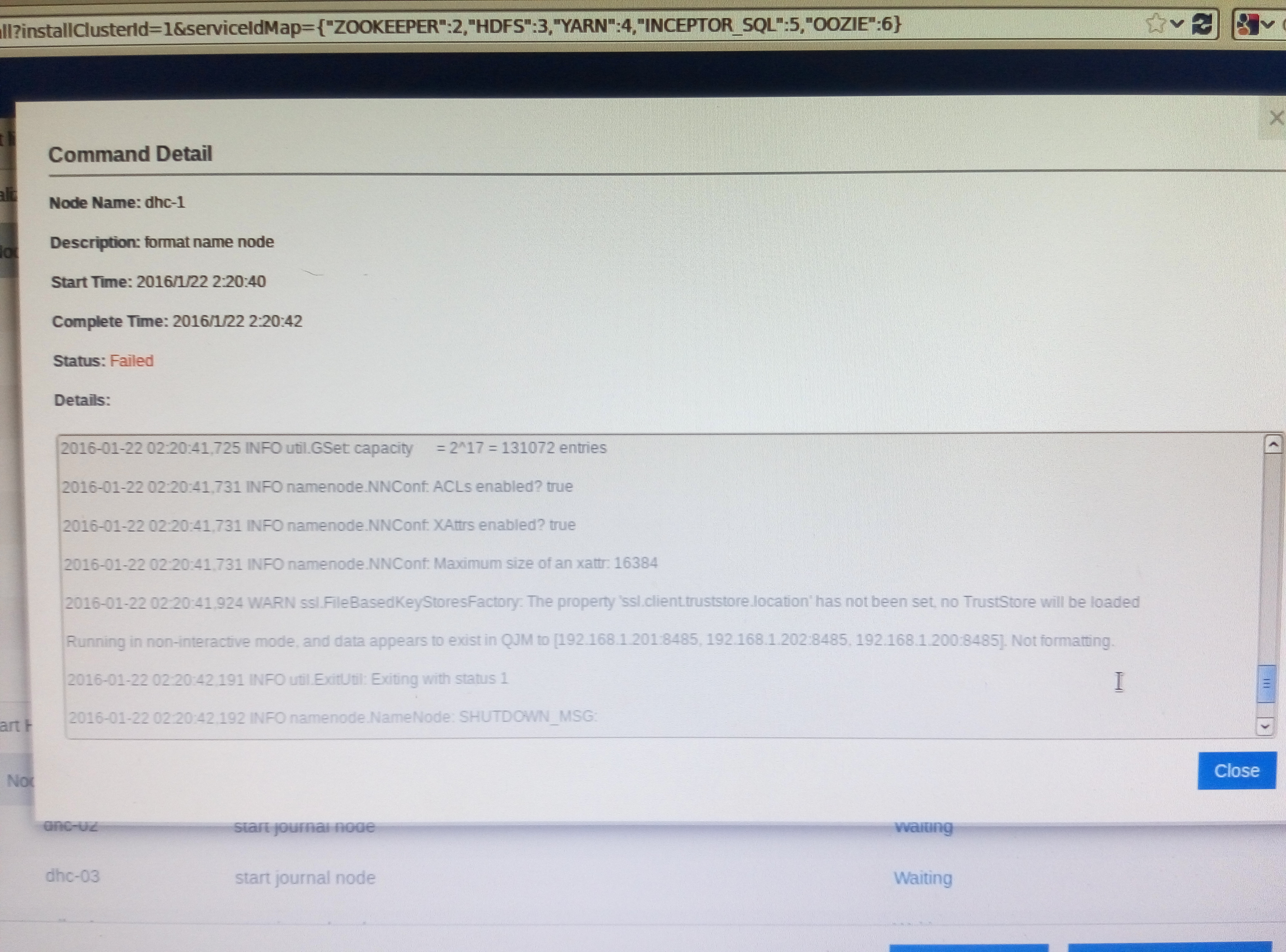
这个错误的解决办法是:
在所有的JournalNode上,删除\/hadoop\/journal中所有的内容,然后执行service hadoop-hdfs-journalnode-hdfs1 restart
在所有NameNode节点上,清空dfs.namenode.name.dir配置的相应目录的所有内容
在所有DataNode节点上,清空dfs.datanode.data.dir配置的相应目录的所有内容
(3)YARN:基础参数中配置yarn.nodemanager.resource.cpu-vcores的CPU核数,配置yarn.nodemanager.resource.memory-mb的内存大小,推荐配置为YARN的核数全给,内存给一半
若CPU若不知道分几个核数,可以在命令行中执行
cat /proc/cpuinfo | grep processor | wc -l
(4)HyperBase:配置master.memory内存大小,(若内存大小为8G,那么这里就应该是8G-YARN的 yarn.nodemanager.resource.memory-mb内存大小),Mastermemory相当于NN,Region server类似于DN,一般Master memory不耗费内存,主要Region server比较耗费内存
(5)Inceptor-SQL(SQL on spark): 高级参数里面可以设置安全护栏,即hive.server.enable,值为FALSE不开启,值为 TRUE后面服务就需要安装kerberos认证了,这项看具体实际需求。另外在资源分配选项中,executor有 Fixed(同构机器,每台机器配置差不多)和Ratio(异构机器,每台机器配置相差很大)两种,一般选择Fixed,下面的内核和内存千万不能超过YARN所设置的内核数和内存大小的值,因为Inceptor-SQL是从YARN那里申请 资源的!推荐配置为内核数:内存=1:2(1个内核配置2GB), Inceptor server节点和Inceptor metastore节点需要安装在同一节点上,若跨节点对表的操作会延迟会很高,Inceptor metastore存储的是表的信息, 记住Inceptor metastore节点的IP地址(即Inceptor server地址)因为使用sqoop服务要在metastore节点上操作mysql数据库(操作之前还需添加mysql的驱动)
六、确认安装后,登陆Inceptor的命令:
beeline -u jdbc:hive2://<Inceptor ip>:10000/
hive1登陆命令为:transwarp -t -h [Inceptor ip]
七、操作数据库
>show databases;
>use database;
>show tables;
>create table country(id int, name string);
安装常见错误汇总:
format namenode出错,造成format namenode失败的原因是因为原TDH没有删除干净,在hadoop\/namenode-dir\/current里面有个锁,删除后可以使用命令etc\/init.d\/hadoop-hdfs-namenode start来启动namenode节点
如果HBase安装不成功,region server报红,首先cd \/usr\/lib\/zookeeper\/bin目录执行zkcli.sh -service [任意一台zookeeper主机ip],再使用rmr \/hyperbase命令将里面的hyperbase目录删除,要注意的是里面的原数据会丢失
Inceptor报黄就去YARN中检查
常用命令:
Manager的相关命令可以使用:service --status-all来查看
显示hdfs集群的命令是:hadoop dfsadmin -report
或者sudo -u hdfs hdfs dfsadmin -reports
使HDFS中数据平衡的命令是:sudo -u hdfs hdfs balancer
产品升级:
1.首先将除zookeeper服务外的其他所有服务都停止,当然前提是已经和使用该集群的用户协调好了
2.该升级只要在manager节点上操作即可,首先进入manager节点环境下,进入\/mnt\/disk1\/transwarp\/support\/script\/upgrade下
3.cat Upgrade.conf
#support 4.1,4.2,4.3,4.3,4.3.1,4.3.2,4.3.4
export OLDVERSION="4.3.2" //旧的版本号
export NEWVERSION="4.3.4" //新的版本号
export MANAGERIP="192.168.1.211" //manager节点的IP
export PORT="8180" //端口
export AGENTHOSTS=("192.168.1.210" "192.168.1.211" "192.168.1.212") //集群节点的IP
export TARPATH="/sunl_update/20160413/transwarp-4.3.4-Final-el6/transwarp-4.3.4-Final-26854-zh.el6.x86_64.tar.gz" //升级所需的压缩包
#support upgrade services:TranswarpManager,Hadoop,Hyperbase,Ngmr
,Inceptor,Stream,Discover,Kafka
export UPGRADESERVICES=("TranswarpManager" "Hadoop" "Hyperbase" "Ngmr" "Inceptor" "Stream" "Discover" "Kafka") //要升级的服务
#1. local os repo
# export USELOCALOSREPO="true"
# export OSREPO="/pub/os"
#2. remote os repo
# export USELOCALREPO="false"
# export OSREPO="http://XXXXXXXX"
export USELOCALOSREPO="true"
export OSREPO="/pub/os"
在\/tmp\/upgrade 下面还有两个脚本,startRevert.sh 这是当升级出错的情况下的回滚脚本,StartUpgrade.sh这是升级脚本,升级的时候要执行该脚本,命令如下:.\/StartUpgrade.sh upgradeCluster ,执行完后会有finish的信息,还可以通过查看updata.log日志是否有错误,来查看是否升级成功
查看版本号方法:
vim /usr/lib/hadoop/hadoop-annotations-2.5.2-transwarp.jar
进入jar包后将光标移至META-INF/MANIFEST.MF回车即可
添加\/删除节点:
添加节点:
管理——节点——搜索节点——自动安装所需服务
删除节点:
管理——节点——查看所要删除节点所依赖的角色——进入服务中的角色中删除节点(删除前必须先停止服务)
Discover安装不成功的解决办法:
| 无法找到Discover插件安装包,请按照以下步骤来解决该问题: 1. 下载并解压 GPL_RPMS-transwarp 安装包至管理节点(manager) 2. 拷贝解压后的 GPL_RPMS 文件夹至管理节点的 \/var\/ftp\/pub\/transwarp 路径下 3. 执行 createrepo \/var\/ftp\/pub\/transwarp 将安装包加入软件库中 |
|---|